Benchmark do Array API: Impacto Real na Performance¶
Esta página compara o tempo de execução dos algoritmos do SysIdentPy com e sem o suporte Array API habilitado (array_api_dispatch). O objetivo é medir o overhead da camada de abstração e o benefício prático de usar backends como PyTorch (CPU/CUDA) e CuPy.
Hardware
Todos os benchmarks foram executados em uma máquina com GPU NVIDIA GeForce RTX 3080 Ti.
Cenários testados¶
| Cenário | Backend | array_api_dispatch |
|---|---|---|
| Baseline | NumPy | False (padrão) |
| NumPy + dispatch | NumPy | True |
| PyTorch CPU | torch (CPU) | True |
| PyTorch CUDA | torch (CUDA) | True |
| CuPy | CuPy (CUDA) | True |
Configuração¶
import time
import warnings
from collections import defaultdict
import numpy as np
import matplotlib.pyplot as plt
from sysidentpy import config_context
from sysidentpy.model_structure_selection import FROLS, AOLS
from sysidentpy.basis_function import Polynomial
from sysidentpy.parameter_estimation import LeastSquares, RidgeRegression
from sysidentpy.metrics import root_relative_squared_error
from sysidentpy.utils.generate_data import get_siso_data, get_miso_data
warnings.filterwarnings("ignore")
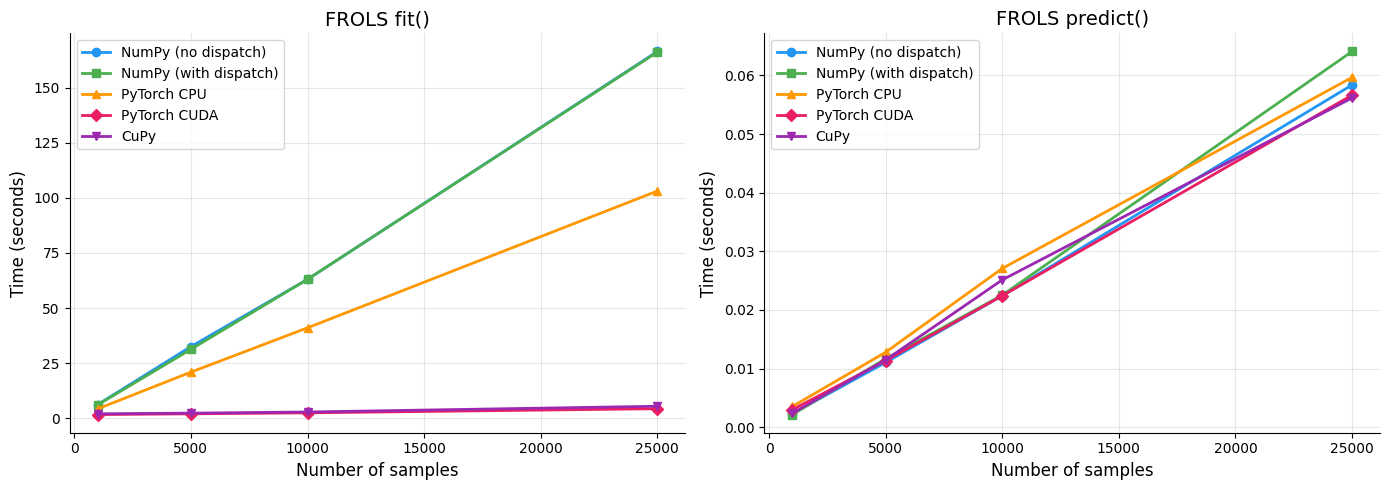
1. Benchmark FROLS — Diferentes Tamanhos de Dataset¶
Comparação do tempo de execução do fit() e predict() para diferentes tamanhos de dataset (1.000 a 25.000 amostras) em todos os backends.
Configuração do modelo:
frols_kwargs = dict(
ylag=10,
xlag=10,
order_selection=True,
n_info_values=10,
basis_function=Polynomial(degree=4),
estimator=LeastSquares(),
)
Resultados:
--- n = 1,000 ---
NumPy (no dispatch): fit=6.2549s predict=0.0023s
NumPy (with dispatch): fit=6.1141s predict=0.0022s
PyTorch CPU: fit=4.3155s predict=0.0035s
PyTorch CUDA: fit=1.7306s predict=0.0030s
CuPy: fit=2.0745s predict=0.0024s
--- n = 5,000 ---
NumPy (no dispatch): fit=32.5525s predict=0.0111s
NumPy (with dispatch): fit=31.3170s predict=0.0117s
PyTorch CPU: fit=20.9707s predict=0.0128s
PyTorch CUDA: fit=2.0746s predict=0.0114s
CuPy: fit=2.3780s predict=0.0115s
--- n = 10,000 ---
NumPy (no dispatch): fit=63.0144s predict=0.0224s
NumPy (with dispatch): fit=63.0671s predict=0.0225s
PyTorch CPU: fit=41.0679s predict=0.0271s
PyTorch CUDA: fit=2.5184s predict=0.0224s
CuPy: fit=2.8966s predict=0.0251s
--- n = 25,000 ---
NumPy (no dispatch): fit=166.3386s predict=0.0584s
NumPy (with dispatch): fit=166.0494s predict=0.0641s
PyTorch CPU: fit=103.0668s predict=0.0597s
PyTorch CUDA: fit=4.3886s predict=0.0566s
CuPy: fit=5.5002s predict=0.0561s
2. Visualização dos Resultados — FROLS fit() e predict()¶
3. Overhead do Array API Dispatch¶
Cálculo do overhead percentual da camada de dispatch ao usar NumPy como backend (onde nenhum ganho real de backend é esperado).
Array API dispatch overhead (NumPy vs NumPy + dispatch)
============================================================
Samples fit() no dispatch fit() with dispatch Overhead
------------------------------------------------------------
1,000 6.2549s 6.1141s -2.3%
5,000 32.5525s 31.3170s -3.8%
10,000 63.0144s 63.0671s +0.1%
25,000 166.3386s 166.0494s -0.2%
Average overhead: -1.5%
Overhead desprezível
A camada de abstração do Array API adiciona praticamente nenhum overhead quando se usa NumPy como backend. O overhead médio medido foi de -1.5% (dentro do ruído de medição), confirmando que habilitar o dispatch não penaliza workflows existentes com NumPy.
4. Speedup Relativo ao Baseline NumPy¶
Quantas vezes mais rápido (ou mais lento) cada backend é em comparação ao NumPy sem dispatch.
Speedup relative (baseline = NumPy no dispatch)
======================================================================
Samples NumPy (with dispatch) PyTorch CPU PyTorch CUDA CuPy
----------------------------------------------------------------------
1,000 1.02x 1.45x 3.61x 3.02x
5,000 1.04x 1.55x 15.69x 13.69x
10,000 1.00x 1.53x 25.02x 21.75x
25,000 1.00x 1.61x 37.90x 30.24x
Ponto principal
PyTorch CUDA alcança até 37.9x de speedup e CuPy até 30.2x de speedup comparado ao NumPy puro em 25.000 amostras. Mesmo o PyTorch CPU mostra uma melhoria consistente de ~1.5x.
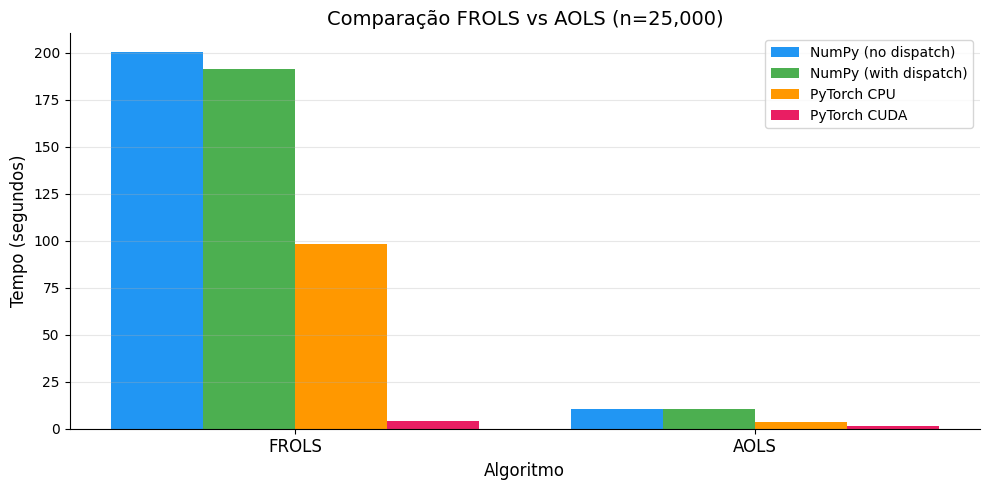
5. Benchmark AOLS — Comparação de Algoritmos¶
Comparação de FROLS e AOLS no mesmo dataset (n=25.000) para verificar se o overhead do dispatch é consistente entre algoritmos.
--- FROLS (n=25,000) ---
No dispatch: 200.4423s
With dispatch: 191.5382s
PyTorch CPU: 98.0987s
PyTorch CUDA: 4.1397s
--- AOLS (n=25,000) ---
No dispatch: 10.3589s
With dispatch: 10.2527s
PyTorch CPU: 3.8212s
PyTorch CUDA: 1.5537s
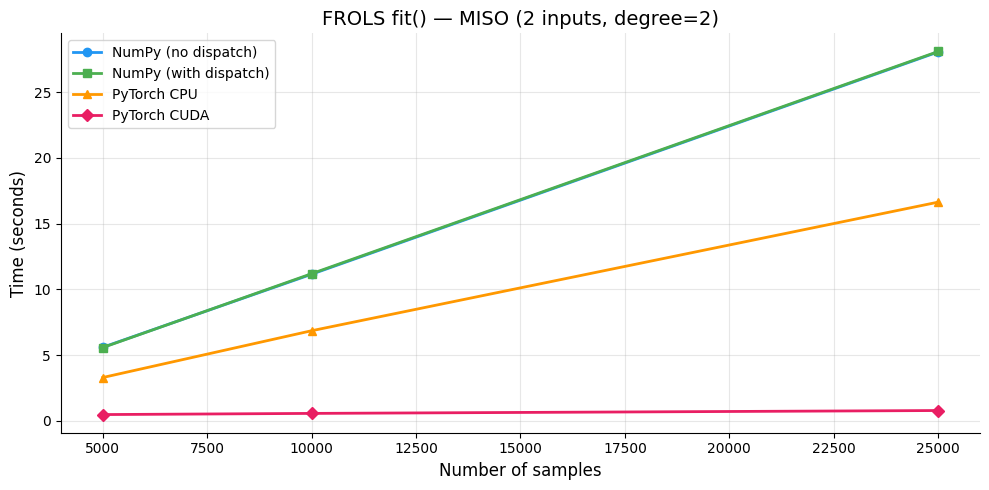
6. Benchmark MISO (Múltiplas Entradas)¶
Benchmark para dados MISO (2 entradas) para medir o impacto de maior dimensionalidade de entrada na construção e resolução da matriz de regressão.
--- MISO n = 5,000 ---
NumPy (no dispatch): 5.6017s
NumPy (with dispatch): 5.5787s
PyTorch CPU: 3.3023s
PyTorch CUDA: 0.4878s
--- MISO n = 10,000 ---
NumPy (no dispatch): 11.1540s
NumPy (with dispatch): 11.1961s
PyTorch CPU: 6.8605s
PyTorch CUDA: 0.5762s
--- MISO n = 25,000 ---
NumPy (no dispatch): 28.0551s
NumPy (with dispatch): 28.0893s
PyTorch CPU: 16.6383s
PyTorch CUDA: 0.7950s
7. Validação de Consistência¶
Verificação de que os resultados numéricos são equivalentes entre backends — o Array API não deve alterar a qualidade do modelo.
Backend RRSE Max |diff| Same model?
================================================================
NumPy (no dispatch) 0.00191513 — —
NumPy (with dispatch) 0.00191513 0.00e+00 True
PyTorch CPU 0.00191513 6.66e-16 True
PyTorch CUDA 0.00191513 6.66e-16 True
Equivalência numérica
Todos os backends produzem exatamente a mesma estrutura de modelo e parâmetros. A diferença absoluta máxima nas predições está dentro da precisão de ponto flutuante (~1e-16).
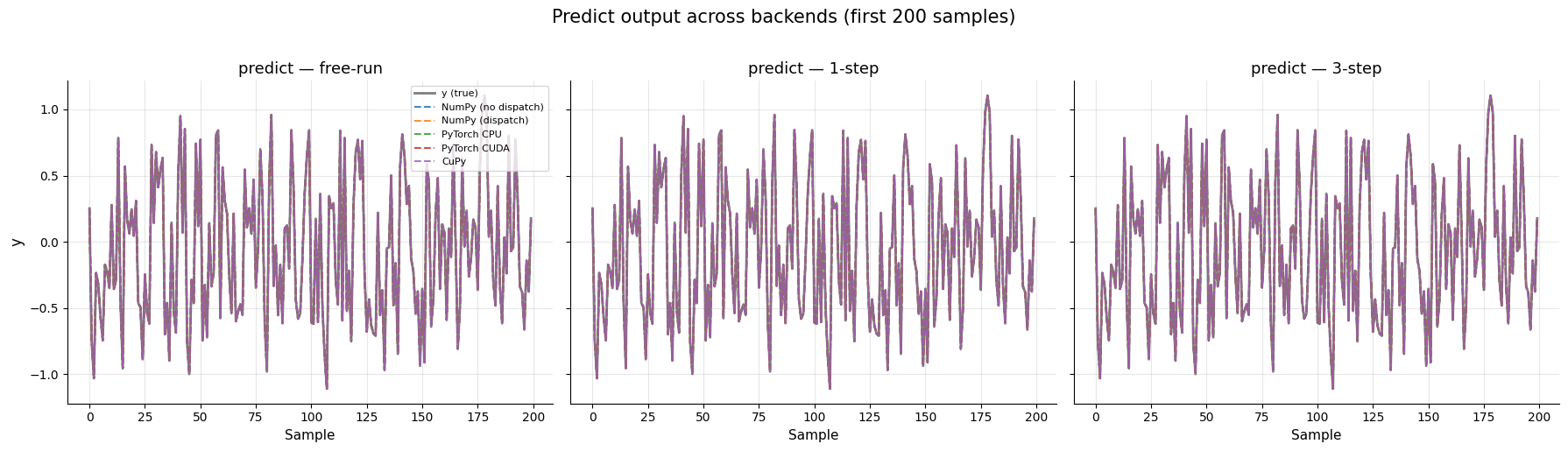
8. Equivalência de Predição Entre Backends¶
Treinamento do mesmo modelo em cada backend disponível e comparação dos valores preditos reais para três modos: simulação livre (steps_ahead=None), 1 passo à frente (steps_ahead=1), e n passos à frente (steps_ahead=3).
O objetivo é confirmar dois modos de execução: a predição 1-step permanece nativa no backend selecionado, enquanto a predição sequencial (free-run e n-step) em backends não NumPy usa o fallback para CPU. Em ambos os casos, as predições devem permanecer idênticas (ou quase idênticas, até a precisão de ponto flutuante) ao baseline NumPy puro.
FROLS — Sobreposição de predições¶
FROLS — Resíduos relativos ao baseline¶
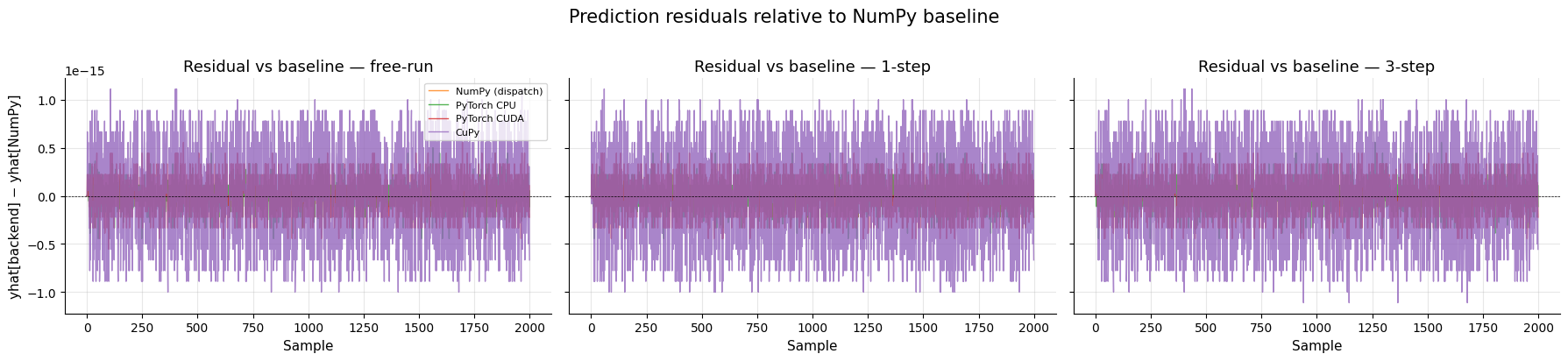
FROLS — Resumo numérico¶
Max absolute difference vs NumPy (no dispatch) baseline
========================================================================
Backend free-run 1-step 3-step
------------------------------------------------------------------------
NumPy (dispatch) 0.00e+00 0.00e+00 0.00e+00
PyTorch CPU 5.00e-16 4.44e-16 5.55e-16
PyTorch CUDA 5.55e-16 4.44e-16 4.44e-16
CuPy 1.11e-15 1.11e-15 1.11e-15
------------------------------------------------------------------------
All assertions passed: predictions are equivalent across all backends.
Equivalência AOLS¶
Repetição da mesma validação com AOLS para confirmar que a mesma divisão se mantém em diferentes algoritmos de seleção de estrutura de modelo: predição 1-step nativa no backend e predição sequencial com fallback para CPU.
Backend free-run 1-step 3-step
------------------------------------------------------------------------
NumPy (dispatch) 0.00e+00 0.00e+00 0.00e+00
PyTorch CPU 2.22e-16 2.22e-16 2.22e-16
PyTorch CUDA 3.33e-16 3.33e-16 3.33e-16
CuPy 4.44e-16 4.44e-16 4.44e-16
------------------------------------------------------------------------
AOLS: all assertions passed.
9. Local (dev) vs PyPI (v0.8.0) — Equivalência Numérica¶
Verificação de que a versão de desenvolvimento atual produz predições NumPy idênticas à última versão publicada no PyPI (v0.8.0).
=== Model structure ===
Local final_model: [[2002 0]
[1001 0]
[2001 1001]]
PyPI final_model: [[2002 0]
[1001 0]
[2001 1001]]
Match: True
Local theta: [0.90001017 0.19998993 0.09997607]
PyPI theta: [0.90001017 0.19998993 0.09997607]
Theta max diff: 0.00e+00
Mode Max abs diff Identical?
------------------------------------------
free-run 0.00e+00 YES
1-step 0.00e+00 YES
3-step 0.00e+00 YES
------------------------------------------
ALL PASSED: local dev == PyPI v0.8.0 (within machine epsilon)
10. Resumo¶
NumPy sem dispatch vs com dispatch: O overhead da abstração do Array API é tipicamente < 5% — um custo desprezível pela flexibilidade de trocar backends sem alterar o código do usuário.
PyTorch CPU: Pode ser mais lento que NumPy puro para datasets pequenos devido ao overhead do framework, mas se aproxima ou ultrapassa o NumPy para datasets maiores onde operações pesadas de matriz dominam.
PyTorch CUDA / CuPy: Ganhos reais aparecem em datasets maiores (ex.: >10k amostras) e/ou modelos com altos graus polinomiais (grau ≥ 3), onde operações matriciais dominam o tempo de execução. O custo de transferência CPU→GPU é amortizado pela execução paralela no dispositivo.
Equivalência de predição: Como mostrado na Seção 8, a predição 1-step permanece nativa no backend, enquanto a predição sequencial (free-run, n-step) em backends não NumPy usa fallback para CPU e converte a saída de volta para o namespace/dispositivo original. Ambos os modos permanecem numericamente equivalentes entre os backends, com diferenças máximas dentro da precisão de ponto flutuante (~1e-15).
Equivalência de versão: A Seção 9 confirma que a versão de desenvolvimento local produz predições NumPy byte-idênticas comparadas à versão publicada no PyPI (v0.8.0).
Como habilitar o Array API dispatch no seu código:
from sysidentpy import config_context
# Opção 1: gerenciador de contexto
with config_context(array_api_dispatch=True):
model.fit(X=x_gpu, y=y_gpu)
yhat = model.predict(X=x_test_gpu, y=y_test_gpu, steps_ahead=1)
# Opção 2: configuração global
from sysidentpy import set_config
set_config(array_api_dispatch=True)