Benchmark de Array API: Impacto Real en el Rendimiento¶
Esta página compara el tiempo de ejecución de los algoritmos de SysIdentPy con y sin el soporte Array API habilitado (array_api_dispatch). El objetivo es medir el overhead de la capa de abstracción y el beneficio práctico de usar backends como PyTorch (CPU/CUDA) y CuPy.
Hardware
Todos los benchmarks fueron ejecutados en una máquina con GPU NVIDIA GeForce RTX 3080 Ti.
Escenarios probados¶
| Escenario | Backend | array_api_dispatch |
|---|---|---|
| Baseline | NumPy | False (por defecto) |
| NumPy + dispatch | NumPy | True |
| PyTorch CPU | torch (CPU) | True |
| PyTorch CUDA | torch (CUDA) | True |
| CuPy | CuPy (CUDA) | True |
Configuración¶
import time
import warnings
from collections import defaultdict
import numpy as np
import matplotlib.pyplot as plt
from sysidentpy import config_context
from sysidentpy.model_structure_selection import FROLS, AOLS
from sysidentpy.basis_function import Polynomial
from sysidentpy.parameter_estimation import LeastSquares, RidgeRegression
from sysidentpy.metrics import root_relative_squared_error
from sysidentpy.utils.generate_data import get_siso_data, get_miso_data
warnings.filterwarnings("ignore")
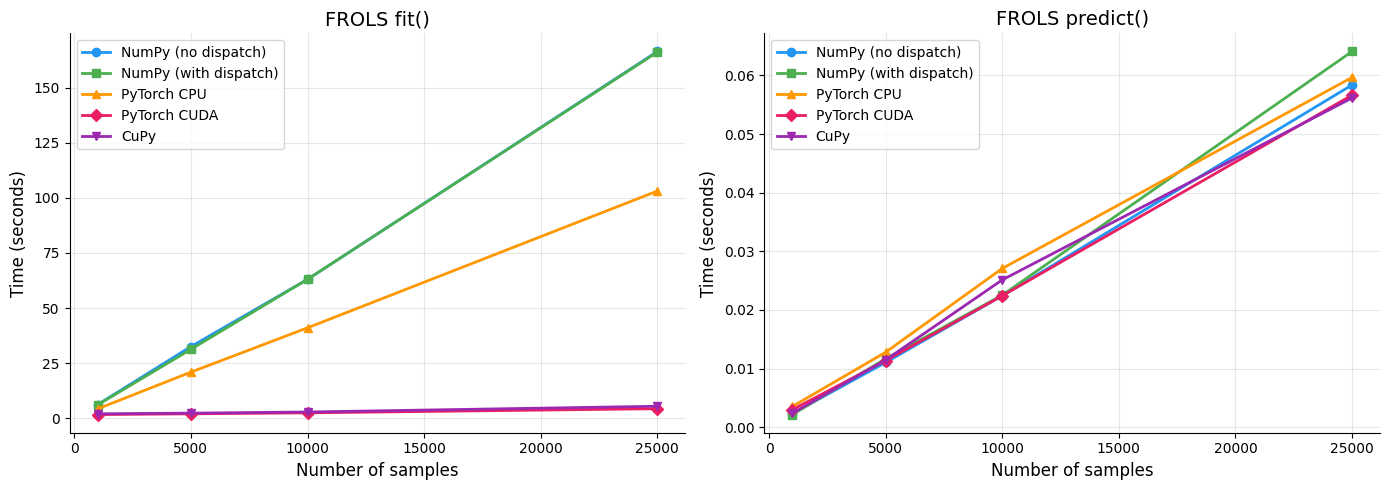
1. Benchmark FROLS — Diferentes Tamaños de Dataset¶
Comparación del tiempo de ejecución de fit() y predict() para diferentes tamaños de dataset (1.000 a 25.000 muestras) en todos los backends.
Configuración del modelo:
frols_kwargs = dict(
ylag=10,
xlag=10,
order_selection=True,
n_info_values=10,
basis_function=Polynomial(degree=4),
estimator=LeastSquares(),
)
Resultados:
--- n = 1,000 ---
NumPy (no dispatch): fit=6.2549s predict=0.0023s
NumPy (with dispatch): fit=6.1141s predict=0.0022s
PyTorch CPU: fit=4.3155s predict=0.0035s
PyTorch CUDA: fit=1.7306s predict=0.0030s
CuPy: fit=2.0745s predict=0.0024s
--- n = 5,000 ---
NumPy (no dispatch): fit=32.5525s predict=0.0111s
NumPy (with dispatch): fit=31.3170s predict=0.0117s
PyTorch CPU: fit=20.9707s predict=0.0128s
PyTorch CUDA: fit=2.0746s predict=0.0114s
CuPy: fit=2.3780s predict=0.0115s
--- n = 10,000 ---
NumPy (no dispatch): fit=63.0144s predict=0.0224s
NumPy (with dispatch): fit=63.0671s predict=0.0225s
PyTorch CPU: fit=41.0679s predict=0.0271s
PyTorch CUDA: fit=2.5184s predict=0.0224s
CuPy: fit=2.8966s predict=0.0251s
--- n = 25,000 ---
NumPy (no dispatch): fit=166.3386s predict=0.0584s
NumPy (with dispatch): fit=166.0494s predict=0.0641s
PyTorch CPU: fit=103.0668s predict=0.0597s
PyTorch CUDA: fit=4.3886s predict=0.0566s
CuPy: fit=5.5002s predict=0.0561s
2. Visualización de Resultados — FROLS fit() y predict()¶
3. Overhead del Array API Dispatch¶
Cálculo del overhead porcentual de la capa de dispatch al usar NumPy como backend (donde no se espera ninguna ganancia real de backend).
Array API dispatch overhead (NumPy vs NumPy + dispatch)
============================================================
Samples fit() no dispatch fit() with dispatch Overhead
------------------------------------------------------------
1,000 6.2549s 6.1141s -2.3%
5,000 32.5525s 31.3170s -3.8%
10,000 63.0144s 63.0671s +0.1%
25,000 166.3386s 166.0494s -0.2%
Average overhead: -1.5%
Overhead despreciable
La capa de abstracción del Array API no añade prácticamente ningún overhead al usar NumPy como backend. El overhead promedio medido fue de -1.5% (dentro del ruido de medición), confirmando que habilitar el dispatch no penaliza los flujos de trabajo existentes con NumPy.
4. Speedup Relativo al Baseline NumPy¶
Cuántas veces más rápido (o más lento) es cada backend en comparación con NumPy sin dispatch.
Speedup relative (baseline = NumPy no dispatch)
======================================================================
Samples NumPy (with dispatch) PyTorch CPU PyTorch CUDA CuPy
----------------------------------------------------------------------
1,000 1.02x 1.45x 3.61x 3.02x
5,000 1.04x 1.55x 15.69x 13.69x
10,000 1.00x 1.53x 25.02x 21.75x
25,000 1.00x 1.61x 37.90x 30.24x
Punto clave
PyTorch CUDA alcanza hasta 37.9x de speedup y CuPy hasta 30.2x de speedup comparado con NumPy puro en 25.000 muestras. Incluso PyTorch CPU muestra una mejora consistente de ~1.5x.
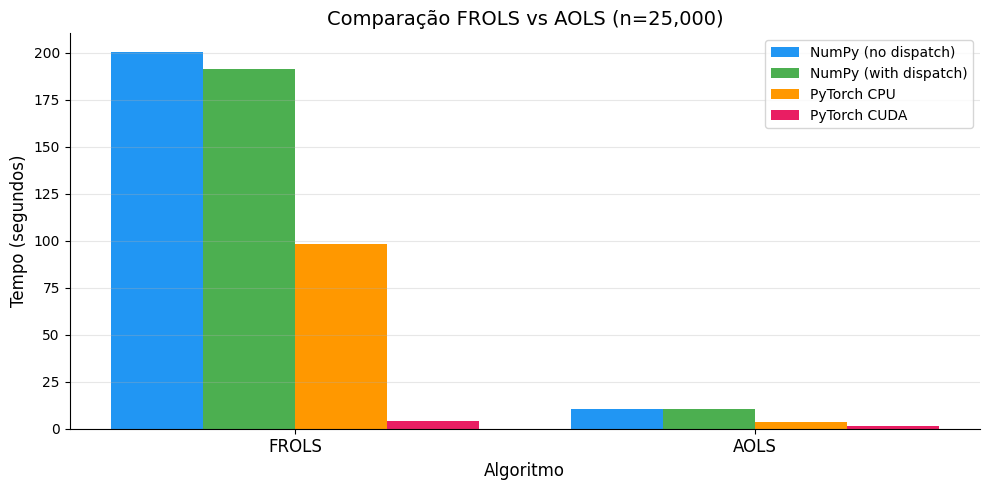
5. Benchmark AOLS — Comparación de Algoritmos¶
Comparación de FROLS y AOLS en el mismo dataset (n=25.000) para verificar si el overhead del dispatch es consistente entre algoritmos.
--- FROLS (n=25,000) ---
No dispatch: 200.4423s
With dispatch: 191.5382s
PyTorch CPU: 98.0987s
PyTorch CUDA: 4.1397s
--- AOLS (n=25,000) ---
No dispatch: 10.3589s
With dispatch: 10.2527s
PyTorch CPU: 3.8212s
PyTorch CUDA: 1.5537s
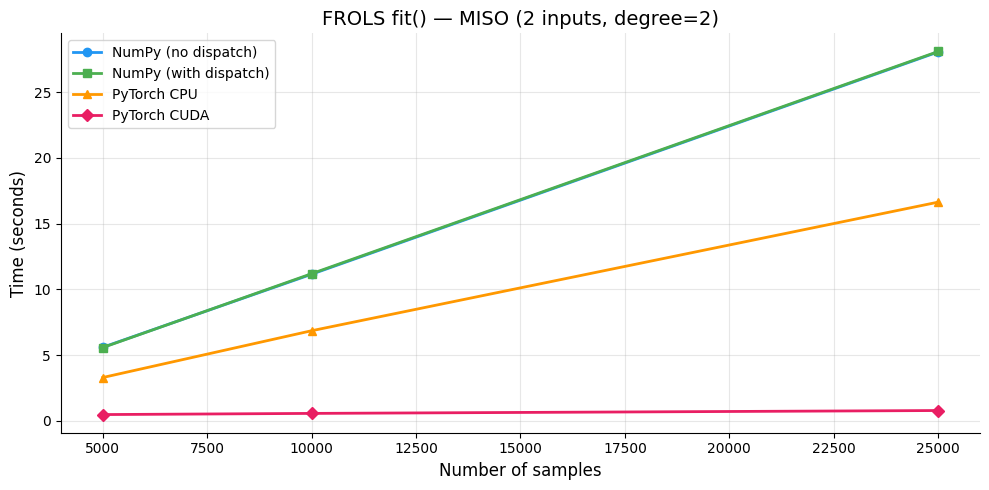
6. Benchmark MISO (Múltiples Entradas)¶
Benchmark para datos MISO (2 entradas) para medir el impacto de mayor dimensionalidad de entrada en la construcción y resolución de la matriz de regresión.
--- MISO n = 5,000 ---
NumPy (no dispatch): 5.6017s
NumPy (with dispatch): 5.5787s
PyTorch CPU: 3.3023s
PyTorch CUDA: 0.4878s
--- MISO n = 10,000 ---
NumPy (no dispatch): 11.1540s
NumPy (with dispatch): 11.1961s
PyTorch CPU: 6.8605s
PyTorch CUDA: 0.5762s
--- MISO n = 25,000 ---
NumPy (no dispatch): 28.0551s
NumPy (with dispatch): 28.0893s
PyTorch CPU: 16.6383s
PyTorch CUDA: 0.7950s
7. Validación de Consistencia¶
Verificación de que los resultados numéricos son equivalentes entre backends — el Array API no debe alterar la calidad del modelo.
Backend RRSE Max |diff| Same model?
================================================================
NumPy (no dispatch) 0.00191513 — —
NumPy (with dispatch) 0.00191513 0.00e+00 True
PyTorch CPU 0.00191513 6.66e-16 True
PyTorch CUDA 0.00191513 6.66e-16 True
Equivalencia numérica
Todos los backends producen exactamente la misma estructura de modelo y parámetros. La diferencia absoluta máxima en las predicciones está dentro de la precisión de punto flotante (~1e-16).
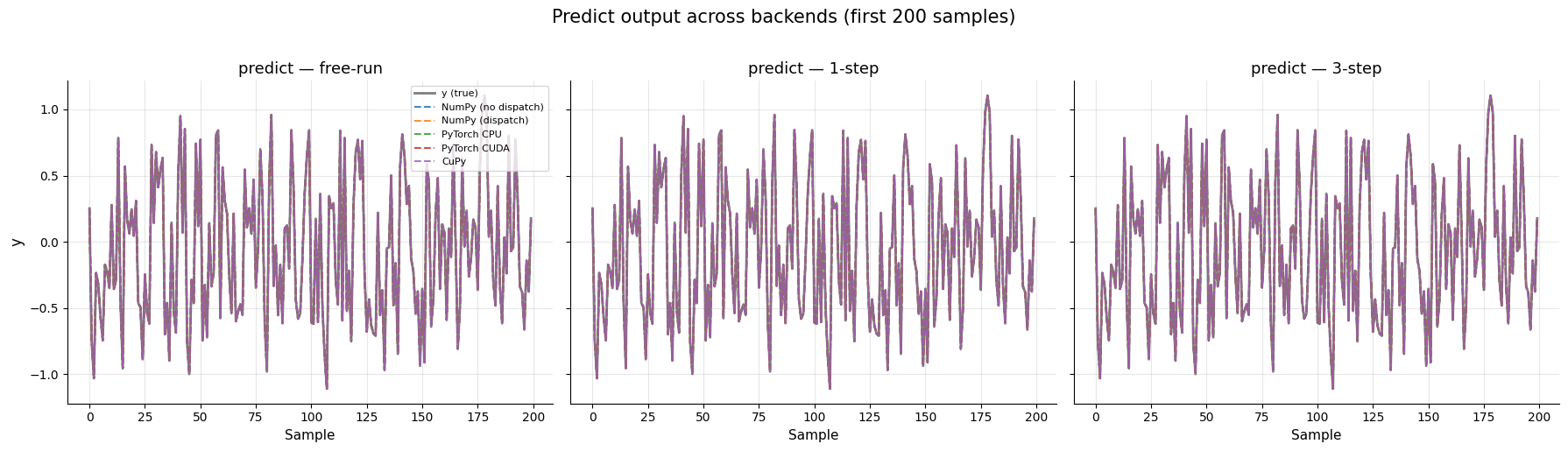
8. Equivalencia de Predicción Entre Backends¶
Entrenamiento del mismo modelo en cada backend disponible y comparación de los valores predichos reales para tres modos: simulación libre (steps_ahead=None), 1 paso adelante (steps_ahead=1), y n pasos adelante (steps_ahead=3).
El objetivo es confirmar dos modos de ejecución: la predicción 1-step permanece nativa en el backend seleccionado, mientras que la predicción secuencial (free-run y n-step) en backends no NumPy usa el fallback a CPU. En ambos casos, las predicciones deben permanecer idénticas (o casi idénticas, hasta la precisión de punto flotante) al baseline de NumPy puro.
FROLS — Superposición de predicciones¶
FROLS — Residuos relativos al baseline¶
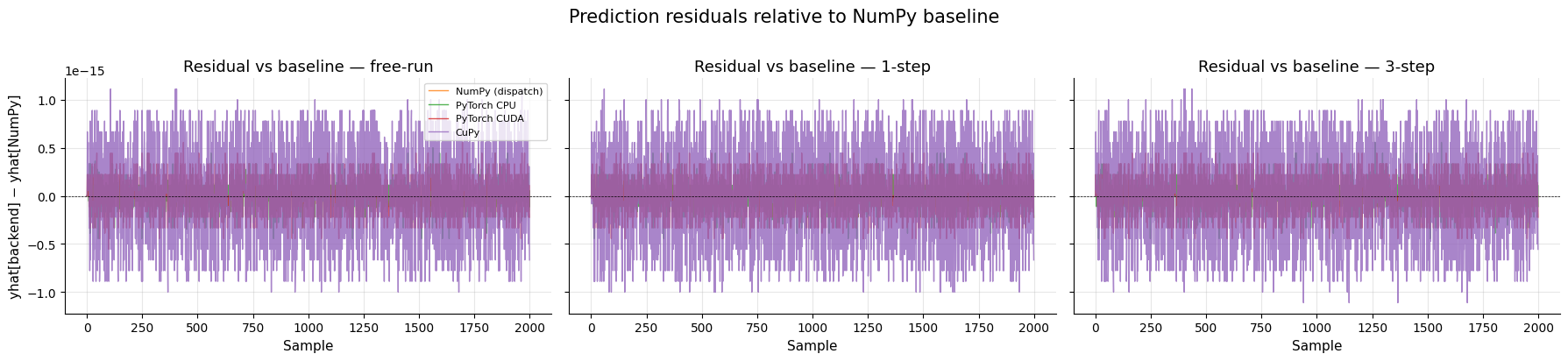
FROLS — Resumen numérico¶
Max absolute difference vs NumPy (no dispatch) baseline
========================================================================
Backend free-run 1-step 3-step
------------------------------------------------------------------------
NumPy (dispatch) 0.00e+00 0.00e+00 0.00e+00
PyTorch CPU 5.00e-16 4.44e-16 5.55e-16
PyTorch CUDA 5.55e-16 4.44e-16 4.44e-16
CuPy 1.11e-15 1.11e-15 1.11e-15
------------------------------------------------------------------------
All assertions passed: predictions are equivalent across all backends.
Equivalencia AOLS¶
Repetición de la misma validación con AOLS para confirmar que la misma división se mantiene en diferentes algoritmos de selección de estructura de modelo: predicción 1-step nativa en el backend y predicción secuencial con fallback a CPU.
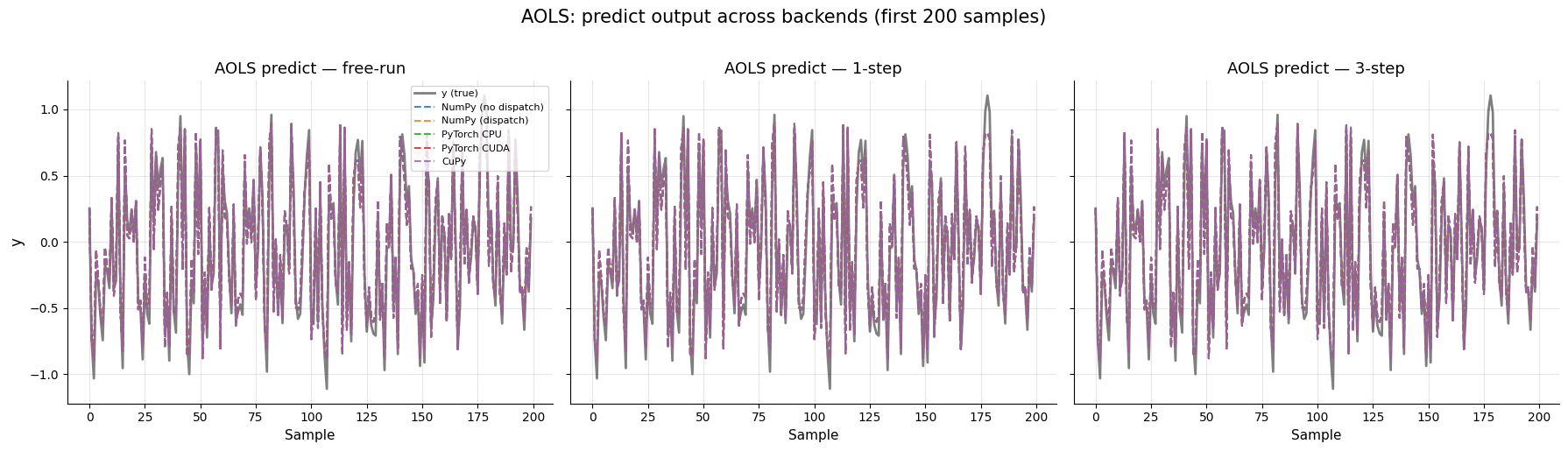
Backend free-run 1-step 3-step
------------------------------------------------------------------------
NumPy (dispatch) 0.00e+00 0.00e+00 0.00e+00
PyTorch CPU 2.22e-16 2.22e-16 2.22e-16
PyTorch CUDA 3.33e-16 3.33e-16 3.33e-16
CuPy 4.44e-16 4.44e-16 4.44e-16
------------------------------------------------------------------------
AOLS: all assertions passed.
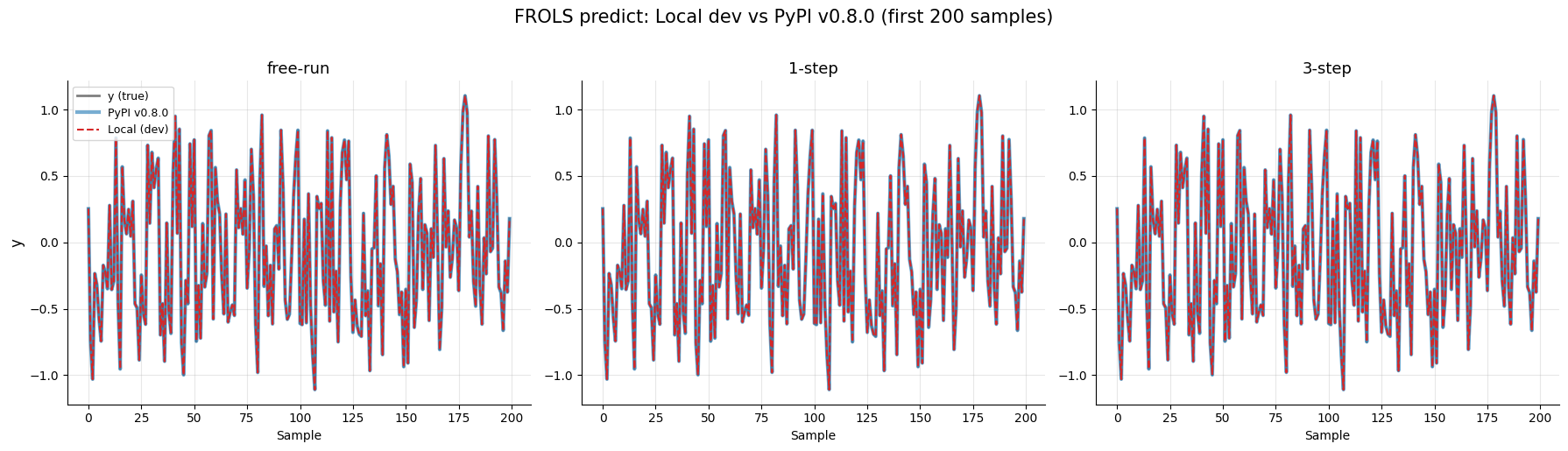
9. Local (dev) vs PyPI (v0.8.0) — Equivalencia Numérica¶
Verificación de que la versión de desarrollo actual produce predicciones NumPy idénticas a la última versión publicada en PyPI (v0.8.0).
=== Model structure ===
Local final_model: [[2002 0]
[1001 0]
[2001 1001]]
PyPI final_model: [[2002 0]
[1001 0]
[2001 1001]]
Match: True
Local theta: [0.90001017 0.19998993 0.09997607]
PyPI theta: [0.90001017 0.19998993 0.09997607]
Theta max diff: 0.00e+00
Mode Max abs diff Identical?
------------------------------------------
free-run 0.00e+00 YES
1-step 0.00e+00 YES
3-step 0.00e+00 YES
------------------------------------------
ALL PASSED: local dev == PyPI v0.8.0 (within machine epsilon)
10. Resumen¶
NumPy sin dispatch vs con dispatch: El overhead de la abstracción del Array API es típicamente < 5% — un costo despreciable por la flexibilidad de cambiar backends sin modificar el código del usuario.
PyTorch CPU: Puede ser más lento que NumPy puro para datasets pequeños debido al overhead del framework, pero se acerca o supera a NumPy para datasets más grandes donde las operaciones pesadas de matrices dominan.
PyTorch CUDA / CuPy: Las ganancias reales aparecen en datasets más grandes (ej.: >10k muestras) y/o modelos con altos grados polinomiales (grado ≥ 3), donde las operaciones matriciales dominan el tiempo de ejecución. El costo de transferencia CPU→GPU se amortiza por la ejecución paralela en el dispositivo.
Equivalencia de predicción: Como se muestra en la Sección 8, la predicción 1-step permanece nativa en el backend, mientras que la predicción secuencial (free-run, n-step) en backends no NumPy usa fallback a CPU y convierte la salida de vuelta al namespace/dispositivo original. Ambos modos permanecen numéricamente equivalentes entre backends, con diferencias máximas dentro de la precisión de punto flotante (~1e-15).
Equivalencia de versión: La Sección 9 confirma que la versión de desarrollo local produce predicciones NumPy byte-idénticas comparadas con la versión publicada en PyPI (v0.8.0).
Cómo habilitar el Array API dispatch en tu código:
from sysidentpy import config_context
# Opción 1: gestor de contexto
with config_context(array_api_dispatch=True):
model.fit(X=x_gpu, y=y_gpu)
yhat = model.predict(X=x_test_gpu, y=y_test_gpu, steps_ahead=1)
# Opción 2: configuración global
from sysidentpy import set_config
set_config(array_api_dispatch=True)